10月28日消息,近期发布的DeepSeek V3.1大模型因搭载了FP8精度格式(UE8M0 FP8)引发业界广泛关注。据华为计算今日透露,河南昆仑技术有限公司(简称“昆仑技术”)基于昇腾AI的Ascend C算子编程语言,研发出一套软FP8解决方案。
据悉,FP8精度格式相比传统的FP16/BF16精度,能够将模型的显存需求直接减半,有效减轻服务器硬件压力;与常见的INT8量化精度相比,不仅推理精度更高,数据表示范围也更广,成功解决了“降成本”与“保效果”之间的核心矛盾。
该方案实现了“精度无损、成本减半”的双重技术突破:
通过将FP8权重模型输入昇腾硬件,利用精准的反量化算子,将其转换为BF16格式参与计算,既确保了计算过程的准确性,又为后续新FP8权重模型的快速适配预留了灵活空间,无需进行权重重度格式转换;
在模型精度几乎无损的前提下,单台KunLun G8600即可流畅运行满血版DeepSeek V3.1模型;即便在KunLun G5500V2、KunLun G5580等标卡机型上,也能实现模型参数规模翻番,同时大幅提升并发处理能力,让不同硬件配置的用户都能享受到FP8推理带来的技术红利。
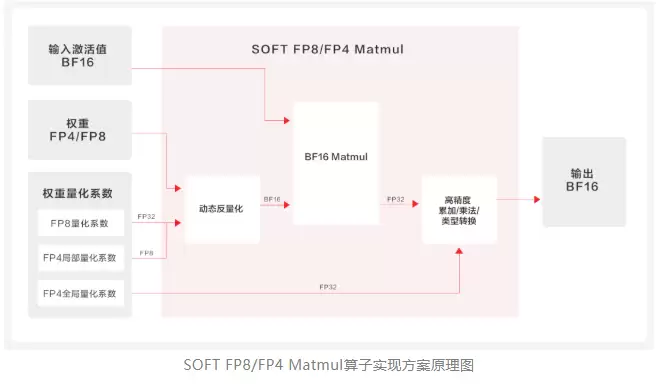
昆仑技术的软FP8解决方案拥有三大核心技术亮点:自研FP8反量化算子,实现显存与内存带宽双减半;算子整图下发,推理效率提升32%;生态级兼容,支持主流模型无缝运行。
从华为计算获悉,KunLun AI Space软FP8解决方案已全面兼容DeepSeek V3.1、DeepSeek-V3 / R1、Qwen3等主流FP8量化模型。同时,该方案具备优异的扩展性,能够快速支持后续新发布的大模型。




