2025年10月24日,生成式人工智能在信息整合方面的潜力已获得广泛认可,其生成的内容时常令人印象深刻。然而经过深入审视后不难发现,这项技术在实际应用中仍存在诸多不足。
近期,欧洲广播联盟与英国公共广播机构联合开展了一项针对主流人工智能系统的评估,重点考察其在新闻摘要生成方面的准确性和可靠性。参与测试的包括ChatGPT、Gemini以及Perplexity等多个备受关注的AI平台。此次研究的背景源于一个值得关注的趋势:目前约有15%的25岁以下人群将人工智能作为获取新闻的主要渠道。
研究初期通过大规模问卷调查及多场专题讨论会,收集公众对AI新闻工具的实际使用反馈与态度。随后,该项目由欧洲广播联盟推动扩展至更广泛的国际层面。结果显示,约42%的英国成年人认为AI生成内容具备准确性,年轻用户群体对该类技术的信任程度更高。但值得注意的是,高达84%的受访者明确表示,一旦发现AI输出存在事实性错误,其信任感将显著下降。因此,关键问题在于:这些系统究竟存在哪些类型的错误,以及用户能否有效识别这些偏差。
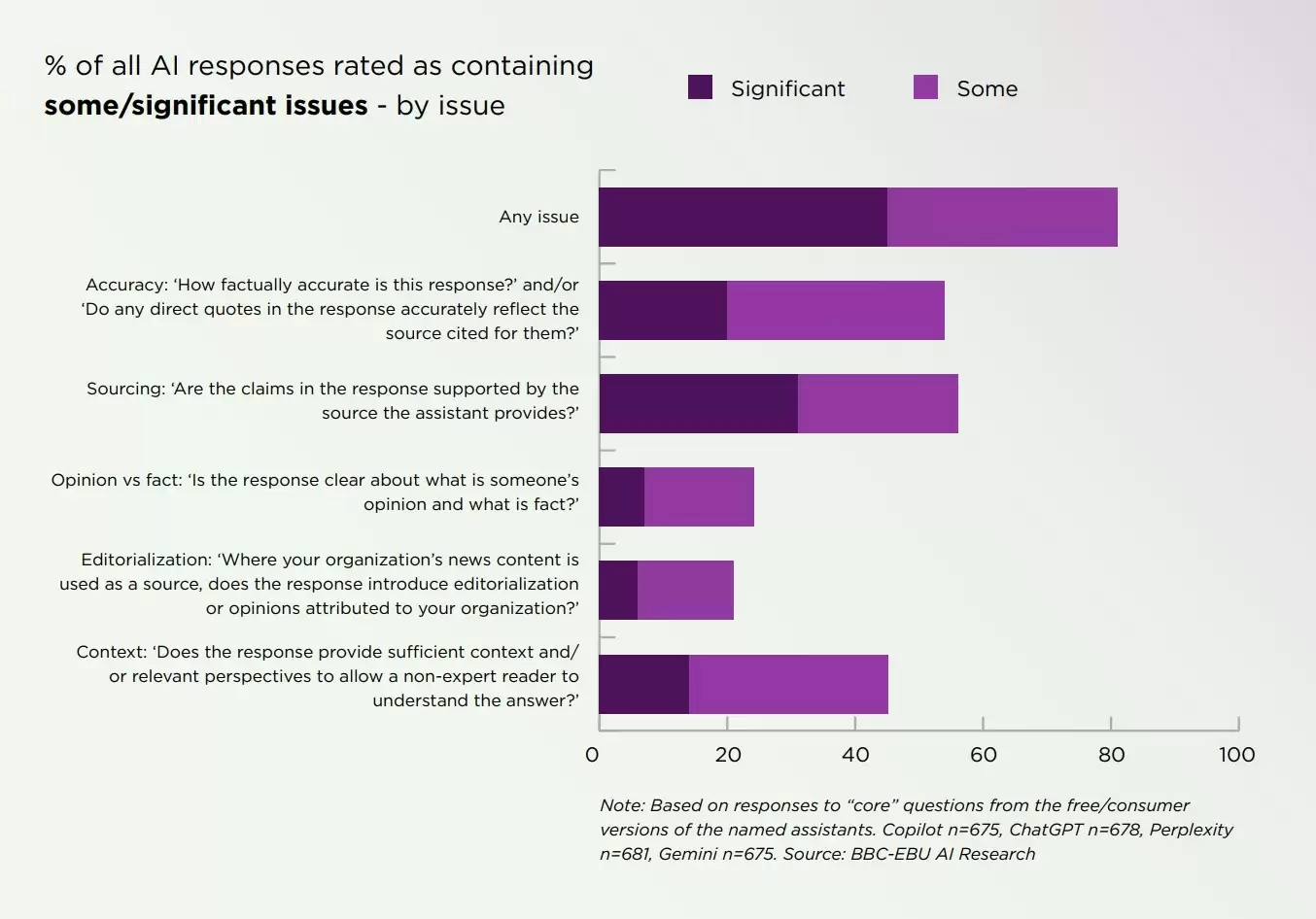
评估发现,多数AI系统在生成新闻摘要时均暴露出不同程度的信息失真问题。整体来看,各模型表现水平接近,但Gemini的表现尤为突出——不仅在错误总量上居首,其所产生的严重事实性错误比例也显著高于其他同类系统。
在为期六个月的测试周期中,所有被测AI系统在新闻摘要的准确性方面均呈现不同程度的提升,其中Gemini的改进进度较为明显。尽管如此,其最终表现依然明显落后于其他参与评估的模型。
相关研究结果已整理成文,供公众查阅,主题为人工智能助手新闻真实性。




