经过数月延期,NVIDIA最新推出的迷你型AI超级计算机DGX Spark终于正式上市。这款设备定价3999美元,折合人民币约3万元起,主要面向专业AI开发与研究场景。
硬件配置方面,DGX Spark搭载了GB10 Grace与Blackwell SuperChip组合架构。其CPU部分采用20核ARM设计,包含10个Cortex-X925核心与10个Cortex-A725核心;GPU基于Blackwell架构,FP4算力达到1PFLOPS,同时集成第五代Tensor核心与第四代实时光线追踪技术,整体规格接近下一代RTX 5070的水平。
系统配备128GB LPDDR5X统一内存,内存位宽为256位,最高运行频率达9400MHz,理论带宽约为301GB/s。这一配置使其能够支持最高2000亿参数的AI大模型推理,或运行高达700亿参数的微调任务,在本地部署大模型方面具备一定潜力。
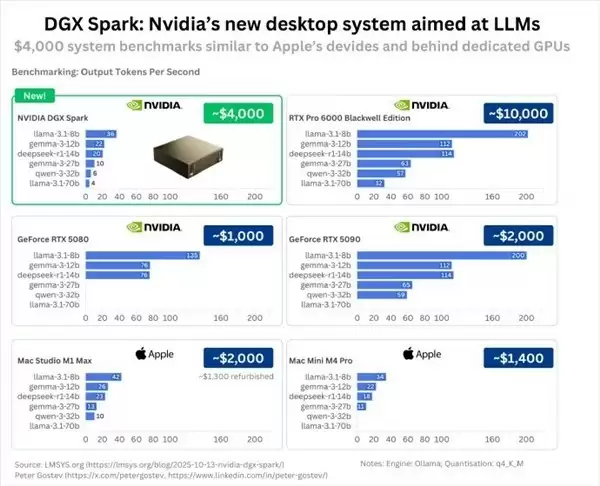
尽管硬件规格亮眼,但实际性能表现却引发争议。已有用户对DGX Spark进行测试,运行包括Deepseek R1、Llama-3、Gemma-3在内的多个主流大模型。测试结果显示,在处理Llama-3.1-8b模型时,输出速度约为每秒36个token,而Deepseek R1仅为每秒20个token。
对比其他高端计算平台,同级别显卡如RTX 5090在相同任务中的表现可达每秒200和114个token,领先幅度达3至5倍,且其售价仅为DGX Spark的一半左右。即便是消费级设备,搭载苹果M4 Pro芯片的Mac Mini在同类任务中也能实现约每秒34和18个token的输出速度,性能与DGX Spark相当,但整机价格仅1400美元。
综合来看,尽管DGX Spark实现了在紧凑设备上运行超大规模模型的能力,但其实际推理性能受限明显,尤其在内存带宽利用效率方面存在瓶颈。相较于其高昂定价和顶级规格,性能回报未达预期,甚至接近价格低至三分之一的其他消费级平台,市场对其性价比和技术优化程度提出了质疑。




