9月24日,阿里云正式发布Qwen3-Max语言模型,这是继Qwen3-2507系列后通义团队推出的最新力作,也是目前该系列中规模最大、性能最强的旗舰级模型。
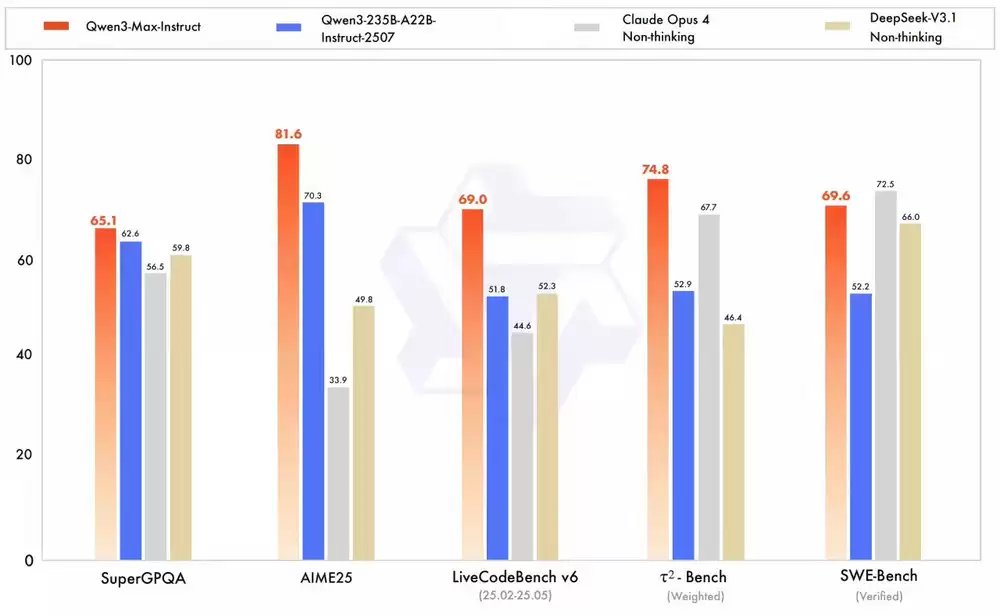
全新推出的Qwen3-Max-Instruct正式版显著提升了代码理解和智能体交互能力。经过全面测试,该模型在专业知识、逻辑推理、程序设计、任务执行、人机交互、智能体协作及多语言处理等领域均展现出业界顶级水准。
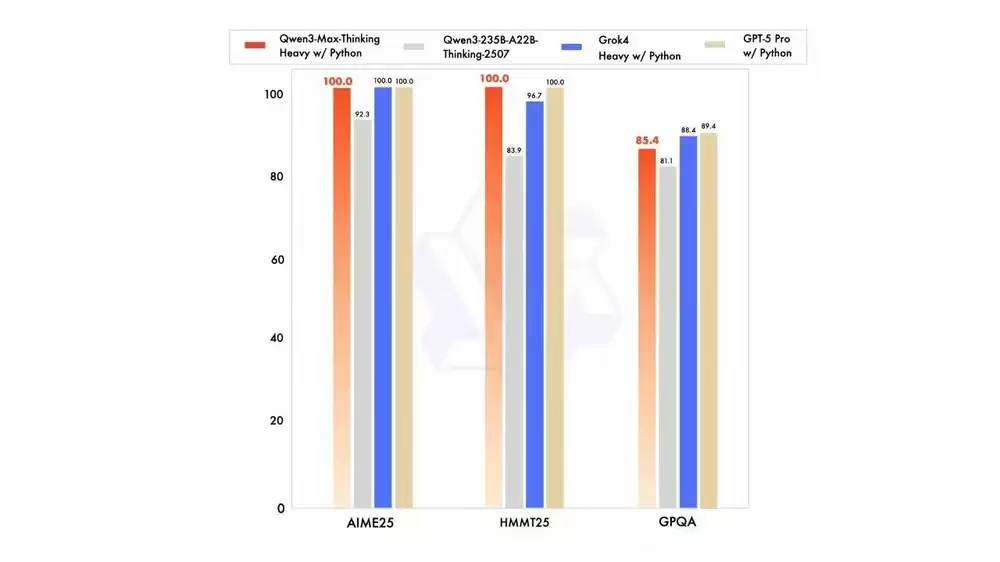
通义团队透露,尚在研发中的Qwen3-Max-Thinking版本已表现出惊人潜质。当配合专属工具并增加运算资源时,这套"思考"系统在AIME 25、HMMT等高难度数学推理测试中实现了100%准确率的完美表现,预计将于近期正式推向市场。
技术资料显示,Qwen3-Max采用超过1万亿参数规模,基于36万亿token进行预训练。模型架构延续Qwen3系列的设计理念,创新性地采用了global-batch负载均衡损失函数。
训练稳定性方面,得益于MoE架构的独特设计,Qwen3-Max在预训练过程中展现出异常平滑的loss曲线,全程无需使用训练回退或数据分布调整等常规优化手段。
在PAI-FlashMoE多级流水并行技术的加持下,Qwen3-Max-Base版本的训练效率较前代Qwen2.5-Max-Base提升达30%。通过ChunkFlow策略优化,长序列训练场景的吞吐量更是传统序列并行方案的3倍,完美支持百万级长上下文训练。
值得注意的是,Qwen3-Max-Instruct预览版已在LMArena文本榜单挺进全球前三,正式发布版本进一步强化了代码生成和智能体任务处理能力。在SWE-Bench Verified真实编程测试中获得69.6的高分,在Tau2-Bench智能体工具调用评测中以74.8分超越Claude Opus 4与DeepSeek-V3.1等主流模型。
其强化版本Qwen3-Max-Thinking通过整合代码解释器和并行计算技术,在AIME 25及HMMT等高难度数学推理评测中创造了100%准确率的惊人纪录。




