高质量训练数据的匮乏已显著制约着大语言模型(LLM)的持续进化与能力突破。
Meta公司最新研发的"语言自我博弈"(Language Self-Play,LSP)强化学习技术开创性地实现了模型的自迭代优化,完全摆脱了对额外训练数据的依赖需求。

自我对抗:双重角色的智能化博弈
该研究重构了传统博弈论框架,将单一LLM分解为两个对抗性角色:"挑战者"负责设计高难度指令,"解题者"致力于提供最优解答。两种角色均由同一基础模型实现,通过持续的自我对抗实现能力跃升。
- 挑战者模块:配备专用提示模板,被要求生成从基础到高阶的多样性测试指令,形成对解题者的系统性考核
- 解题者模块:需通过生成高质量回复来获得评估奖励,奖励机制包含客观指标与主观偏好双重维度
核心技术创新
研究团队引入了两项关键技术确保训练过程的稳定性:
- 群体相对策略优化(GRPO):建立动态评价基准,通过批量生成-评估机制量化模型表现
- KL散度约束:有效防止模型偏离预期演进轨道,维持语义生成的合理性
版本迭代:从基础框架到成熟方案
研究过程呈现出明显的技术进化轨迹:
- LSP-Zero原型:初期版本存在"对抗性退化"风险,模型可能陷入无意义的奖励黑客行为
- LSP正式版:引入七维质量评估体系,从指令明确度到响应实用性进行多角度约束
实证研究与性能突破
基于Llama-3.2-3B-Instruct的实验数据显示:
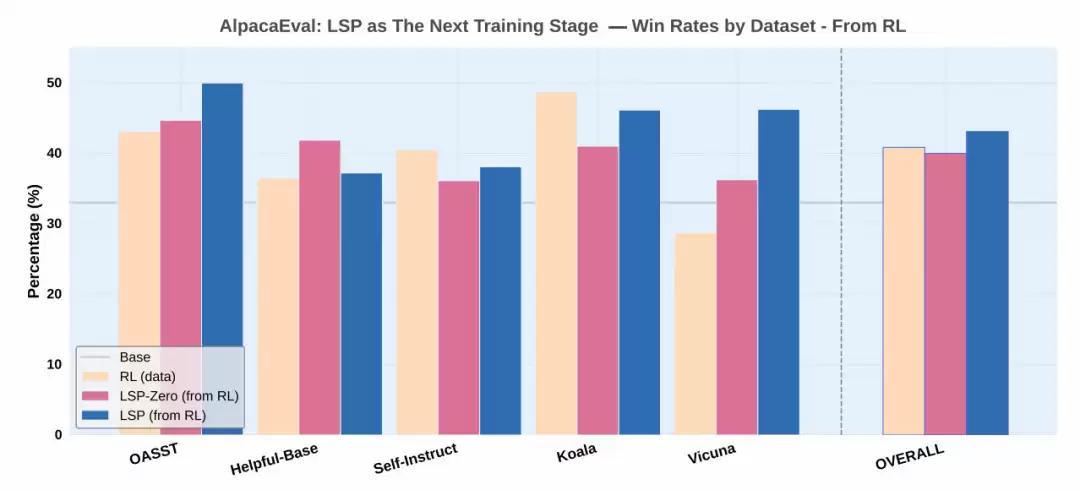
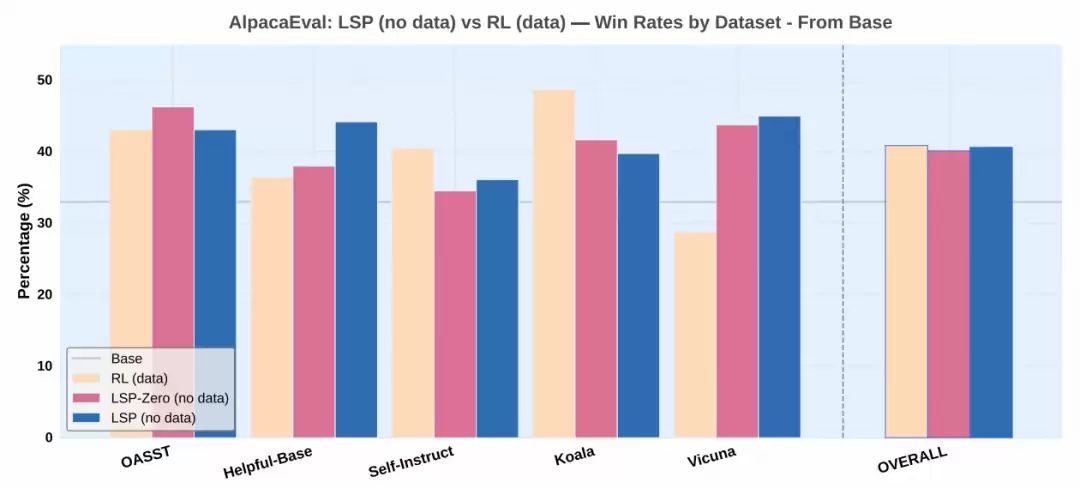
- 在AlpacaEval基准测试中,LSP模型胜率达40.6%,与数据驱动的GRPO方法(40.9%)相当
- Vicuna对话任务场景下,LSP表现尤为突出,胜率较基础模型提升18%
- 作为后续优化器使用时,可将GRPO模型的40.9%胜率进一步提至43.1%
应用前景与研究局限
此项技术突破带来的核心价值包括:
- 降低90%以上的数据准备成本
- 在医疗、法律等数据敏感领域开辟新可能
- 为模型自动化演进提供可行路径
目前存在的局限性主要体现在:
- 对非结构化对话场景(如Koala数据集)适应性有待提升
- 查询风格的多样性需要进一步优化