DeepSeek 登上 Nature 封面实至名归!今年年初,由梁文锋带领的研究团队发布的 DeepSeek-R1 开创性地应用纯强化学习方法,成功突破了大语言模型的推理能力边界。这项革新性研究不仅获得 Nature 期刊的高度认可,还特别配发了评论文章予以赞赏。
最新消息显示,DeepSeek-R1 的最新研究成果登上了 Nature 杂志封面!

今年 1 月发表的论文《DeepSeek-R1: 通过强化学习激发大语言模型推理能力》,如今已成为全球顶级学术期刊的封面研究。

这篇由通讯作者梁文锋领导的论文,通过创新的强化学习框架为大模型推理能力开发开辟了全新路径。
论文地址:https://www.nature.com/articles/s41586-025-09422-z
在封面推荐语中,Nature 毫不吝啬地盛赞了这项研究的创新价值。

值得注意的是,研究团队首次公开了训练成本细节——仅29.4万美元,这个数字令人惊叹。

即便算上约600万美元的基础模型成本,仍显著低于行业巨头OpenAI和谷歌的训练投入。在开源后,R1迅速成为Hugging Face平台最受欢迎的模型,下载量突破1090万次。更重要的是,它成为首个经过完整同行评审的主流大模型。
从预印本论文到登上顶级期刊封面,DeepSeek团队再次用实力证明了AI推理技术的发展潜力。

创新的训练方法论
研究团队抛弃了传统依赖人类示范数据的思路,采用纯强化学习方案。他们选择跳过监督微调(SFT)阶段,直接基于DeepSeek-V3基础模型,构建了一个极简的强化学习框架。

该框架主要包含两个核心要素:
1. 任务格式规范:要求回答必须包含封装在
在这个没有预设解题步骤的训练环境中,DeepSeek-R1展现出了惊人的自主进化能力。在AIME 2024测试中,其准确率从初始的15.6%大幅跃升至77.9%,配合自洽解码技术更达到86.7%。

技术实现细节
研究团队创造性地采用GRPO(组相对策略优化)算法替代传统的PPO方法。这种算法允许多个答案组内竞争,显著降低了计算资源消耗。
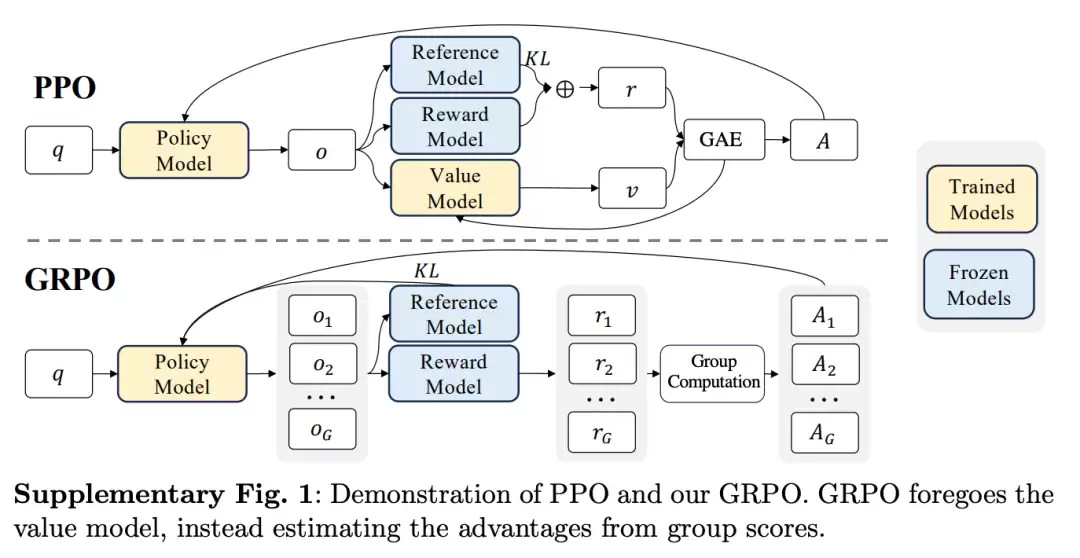
在奖励机制设计上,团队采用双轨制: 1. 严格基于规则的评测系统用于数学、编程等结构化任务; 2. 偏好学习模型用于评估通用任务的回答质量。

训练过程分阶段进行:最初专注于推理能力培养,后续引入多样化任务数据,最后通过偏好对齐优化模型表现。特别调整包括将上下文窗口从32k扩展至65k token,显著提升了模型性能。

学界评价与影响
Nature审稿人Lewis Tunstall表示:"开创性地展示了仅靠强化学习就能获得卓越性能。R1带来的方法论革新正在引发一场革命。"

俄亥俄州立大学研究员Huan Sun评价:"DeepSeek提供的解释在现有文献中具有最高的可信度。"

参考资料: https://www.nature.com/articles/s41586-025-09422 https://www.nature.com/articles/d41586-025-03015-6




