本文深入分析了服务启动初期CPU负载飙高的现象,通过系统性排查最终找到了问题根源并提出了有效解决方案。文章重点阐述了问题的诊断思路与技术细节,尤其突出了火焰图和Arthas工具在性能分析中的关键作用。

以下为关键要点图示:
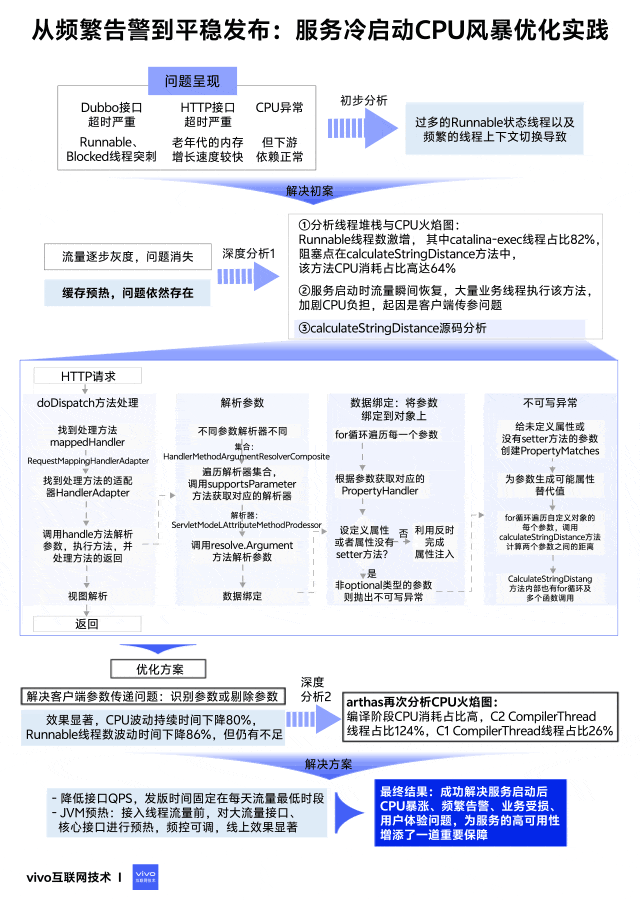
一、问题背景
近期服务在发布或重启过程中频繁出现告警,这种现象从发版开始一直持续到结束后的数分钟。我们最初怀疑是流量接入过快所致。在与运维团队沟通后,将流量接入延迟30秒仍未能解决问题。
二、问题现象
以某次具体发布为例(2024-09-04 16:09:50启动):
- Dubbo接口超时严重(16:14:07-16:17:31共578次超时)
- HTTP接口P95响应时间从几十毫秒飙升至数秒
- CPU使用率在流量接入后接近100%,16:17:30后恢复正常
- Runnable线程数从249激增至1026
- Blocked线程数出现明显突刺
- GC老年代内存从985MB增长至1.36GB
三、初步诊断
监控数据显示:
- 线程数量不足以处理突发流量
- 频繁的线程上下文切换导致CPU饱和
四、解决方案验证
4.1 流量灰度实验
采取1%-5%-44%-100%的渐进式放量策略后,各项指标趋于稳定。证明流量控制能有效缓解问题。
4.2 缓存预热尝试
预热业务缓存后效果不明显,需寻找更深层次原因。
五、深度分析
5.1 Spring框架性能瓶颈
通过线程堆栈分析发现:
- 29%线程(462个)处于Runnable状态
- 201个线程阻塞在PropertyMatches.calculateStringDistance方法
- CPU火焰图显示该方法消耗64.15%的CPU资源
问题根源:
- 客户端透传大量未定义属性
- Spring在属性注入时频繁计算字符串相似度
优化方案:
- 在底层Request中接收公共参数
- 在Filter层过滤非必要字段
- 优化后CPU峰值时长从5分钟缩短至1分钟
5.2 JIT编译瓶颈
二次分析发现:
- C2编译器线程占用大量CPU
- 热点代码编译引发性能瓶颈
最终解决方案:
- 接口请求限流+错峰发布
- JVM预热:启动后主动调用核心接口
六、经验总结
本案例展示了:
- 系统性性能分析的完整流程
- 火焰图和Arthas工具的实战应用
- 从表象到本质的问题溯源方法
关键启示:
- 规范请求参数定义
- 重视服务预热机制
- 建立完善的监控体系




