本文将介绍一套基于用户及产品向量嵌入的实时推荐系统,由BigQuery(Google Cloud完全托管的PB级数据仓库)及Spanner(Coogle Cloud完全托管、适合关键任务的全局规模数据库)提供支持。

译者 | 核子可乐
审校 | 重楼
作为众多行业中不可或缺的组成部分,产品推荐系统对于提供商和消费者而言至关重要,堪称消费体验与销售额提升的助推器。
企业会收集并分析大量使用情况与行为数据,借此优化购买推荐与用户满意度。而一旦推荐不准或者不及时,则可能引发销售损失并拉低消费者体验。
本文将介绍一套基于用户及产品向量嵌入的实时推荐系统,由BigQuery(Google Cloud完全托管的PB级数据仓库)及Spanner(Coogle Cloud完全托管、适合关键任务的全局规模数据库)提供支持。
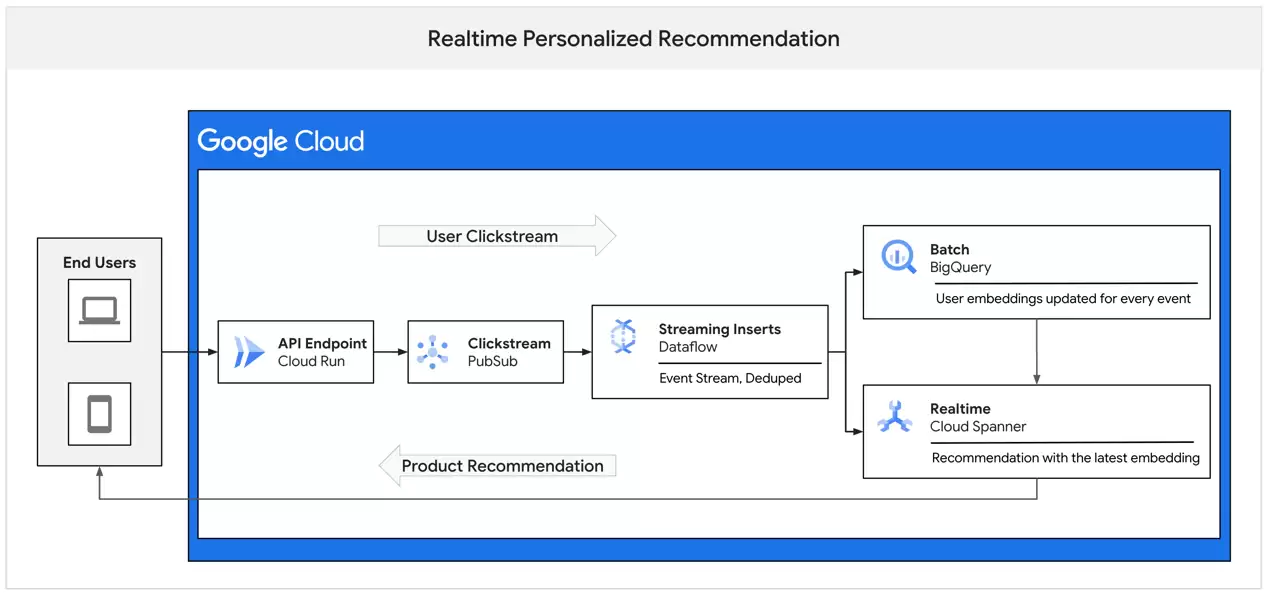
向量嵌入
向量嵌入在生成推荐中扮演着关键角色,它基于用户与产品或服务间的交互来捕捉用户行为、偏好和意图,进而表示产品或服务的特征及属性。向量嵌入会将用户和产品表示为高维数值向量,并通过计算各向量间的距离以衡量产品间、用户间以及产品与用户间的相似性。
以下图为例,其中一张是棒球与球棍,另一张则是钓鱼器具。将这些图片输入Gemini,并要求大模型“为两张图片生成一个64维几量嵌入,使两个嵌入的维度保持一致”,即可为其生成JSOn数组,且维度与下图中维度标签的描述相同。

这时假定用户首先与棒球图片交互,我们可以将棒球嵌入与用户现有嵌入进行聚合以更新用户嵌入(假设用户嵌入具有相同维度)。在此示例中,我们使用简单的平均值进行聚合(大家可选择更符合自身业务需求的方式)。在与渔具图像交互后,系统会取两个嵌入向量的平均值,并将其应用于用户嵌入。更新后的向量如下所示:
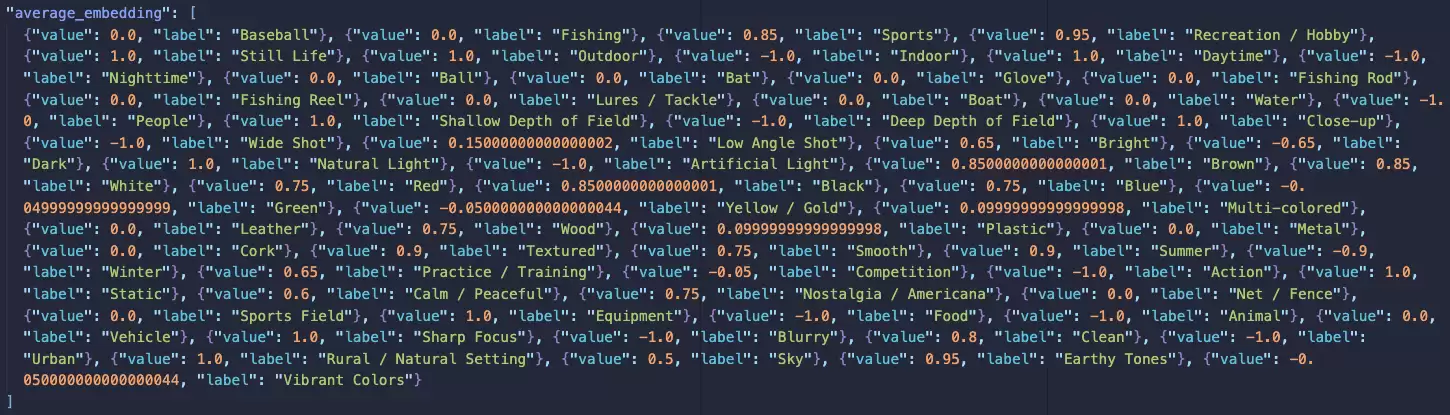
使用BigQuery进行批处理
或应用上的管线数据量可能非常巨大。根据用户交互情况,大多数用户可能并不需要立即获取产品推荐。我们使用目标嵌入(如图片、横幅、按钮等 及应用元素)在BigQuery中收集并批量处理这些高容量、高速度交互数据。之后,我们使用先前计算的用户嵌入执行滚动聚合,以更新最终用户嵌入。这些用户嵌入随后会被推送至Spanner(通过反向ETL机制),以针对特定用户ID进行实时产品推荐。
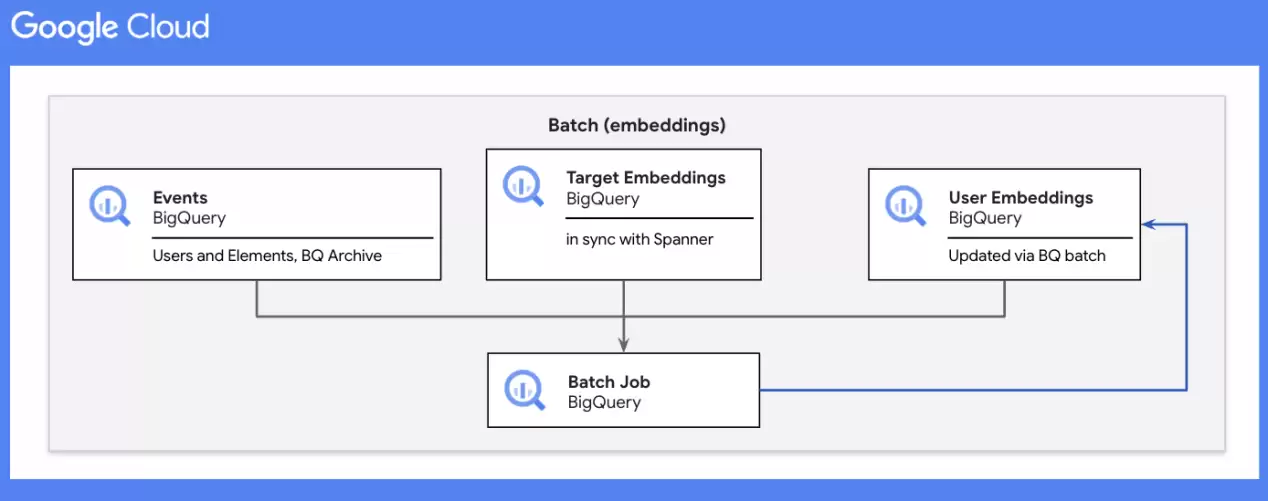
批处理步骤如下:
在特定批处理时长内获取不同用户ID,这能减少后续步骤从用户表扫描的数据量。在给定批处理时长内,将事件表与目标表对接起来,以将目标嵌入映射至各用户-目标交互。将所有映射嵌入与用户表中相应的用户ID进行合并。计算各用户在每个维度上的嵌入的滚动平均值。将更新后的嵌入添加至用户表内。----------------------------------------------------------------------------------------------- BQ Schema :----------------------------------------------------------------------------------------------- dataset.events-- user_id String,-- target_id String,-- ts Timestamp-- dataset.targets-- target_id String,-- target_emb String-- dataset.users-- user_id String,-- emb String,-- last_updated_ts Timestamp---------------------------------------------------------------------------------------------WITH -- STEP 1 dist_user_ids AS ( SELECT DISTINCT events.user_id, FROM dataset.events WHERE events.ts >= $curr_batch_ts), -- STEP 2 user_target_emb AS ( SELECT events.user_id, 1 AS target_count, targets.target_emb AS emb, FROM dataset.events events JOIN dataset.targets targets ON events.target_id = targets.target_id WHERE events.ts >= $curr_batch_ts -- STEP 3 UNION ALL SELECT usres.user_id, users.target_count, users.emb, FROM dataset.users users JOIN dist_user_ids ON users.user_id = dist_user_ids.user_id), -- STEP 4 emb_average AS ( SELECT user_target_emb.user_id, idx, SUM(user_target_emb.target_count) AS target_count, SUM(user_target_emb.target_count * emb_val)/SUM(user_target_emb.target_count) new_emb_val FROM user_target_emb, UNNEST(user_target_emb.emb) emb_val WITH OFFSET AS idx GROUP BY 1, 2), updated_user_embeddings AS ( SELECT user_id, ANY_VALUE(target_count) AS target_count, ARRAY_AGG(new_emb_val ORDER BY idx) AS new_emb FROM emb_average GROUP BY 1 ) -- STEP 5SELECT user_id, target_count, new_emb AS emb, CURRENT_TIMESTAMP() AS last_updated_tsFROM updated_user_embeddings;
用Spanner实现实时推荐
最新批次的更新用户嵌入将通过反向ETL推送至相应Spanner表内。目标嵌入的对应表也在Spanner中维护。
Spanner中仅当时间戳比BigQuery中正在处理的当前批次更晚(更新)时,才需要读取事件流数据。我们可以设置作业或分配TTL标记以定期清理此表。
除事件、用户及目标表之外,我们还须维护资产表,其中包含用于个性化推荐的预测资产。这些资产拥有自己的嵌入,且与用户及目标嵌入的维度相匹配。
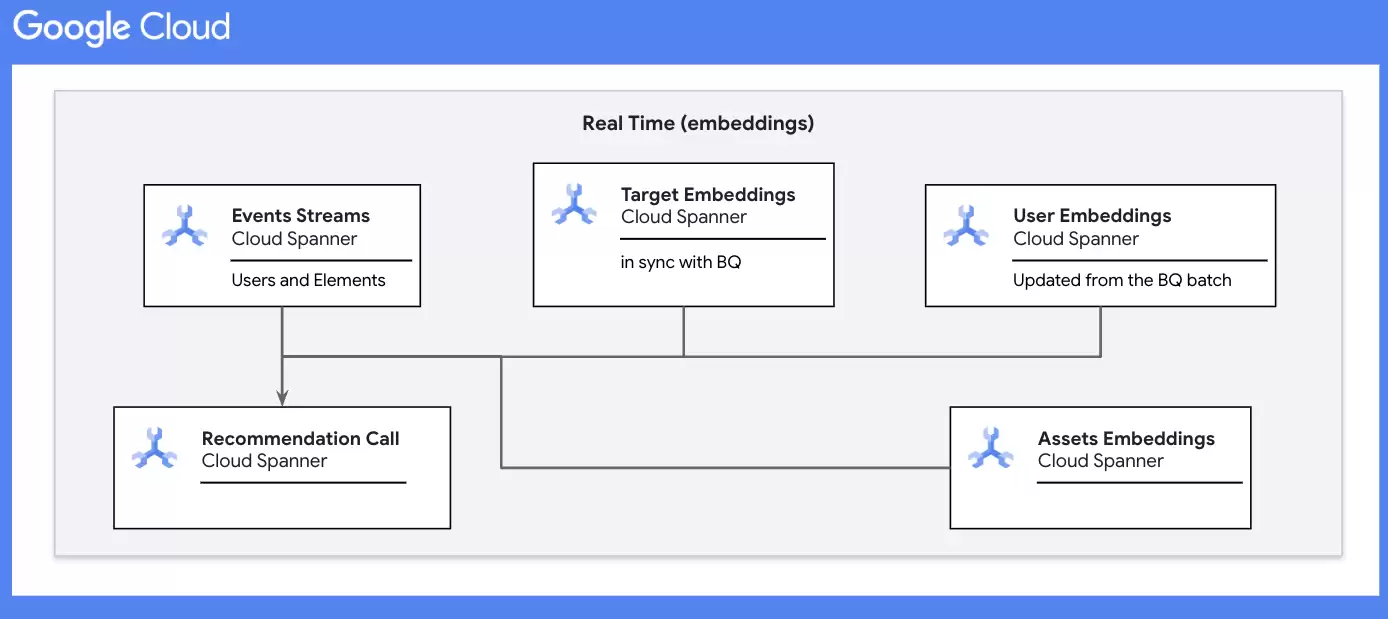
当前端针对给定用户发出预测调用时:
该用户的全部最新事件将与目标表对接,以将目标嵌入映射至各用户-目标交互。将所有映射的嵌入与用户表内相应的用户ID进行合并。计算给定用户在各维度上的嵌入的最终滚动平均值。之后使用最终用户嵌入计算与资产间的距离。返回n个最接近的资产,作为个性化推测预测的内容。--------------------------------------------------------------------------------------------- -- Spanner Schema : --------------------------------------------------------------------------------------------- -- events -- user_id String, -- target_id String, -- ts Timestamp -- targets -- target_id String, -- target_emb String -- users -- user_id String, -- emb String, -- last_updated_ts Timestamp -- assets -- asset_id String, -- asset_emb String, ---------------------------------------------------------------------------------------------WITH -- STEP 1 user_target_emb AS ( SELECT events.user_id, 1 AS target_count, targets.target_emb AS emb, FROM events JOIN targets ON events.target_id = targets.target_id WHERE events.user_id = "$user_id" -- STEP 2 UNION ALL SELECT usres.user_id, users.target_count, users.emb, FROM users WHERE users.user_id = "$user_id" ), -- STEP 3 emb_average AS ( SELECT idx, SUM(user_target_emb.target_count * emb_val)/SUM(user_target_emb.target_count) new_emb_val FROM user_target_emb, UNNEST(user_target_emb.emb) emb_val WITH OFFSET AS idx GROUP BY 1), updated_user_embeddings AS ( SELECT ARRAY_AGG(new_emb_val ORDER BY idx) AS new_emb FROM emb_average ), -- STEP 4 distances AS ( SELECT asset_id, EUCLIDEAN_DISTANCE(( SELECT new_emb FROM updated_user_embeddings), assets.asset_emb) AS distance, FROM assets) -- STEP 5SELECT asset_id, distanceFROM distancesORDER BY 2 DESCLIMIT $n
总结
根据业务需求及规则条款,前端系统将决定向用户展示哪些产品作为最终推荐。具体方式可以只考虑最短距离,也可以用更复杂的方式对预测结果进行重新排序。
综合流程图如下:
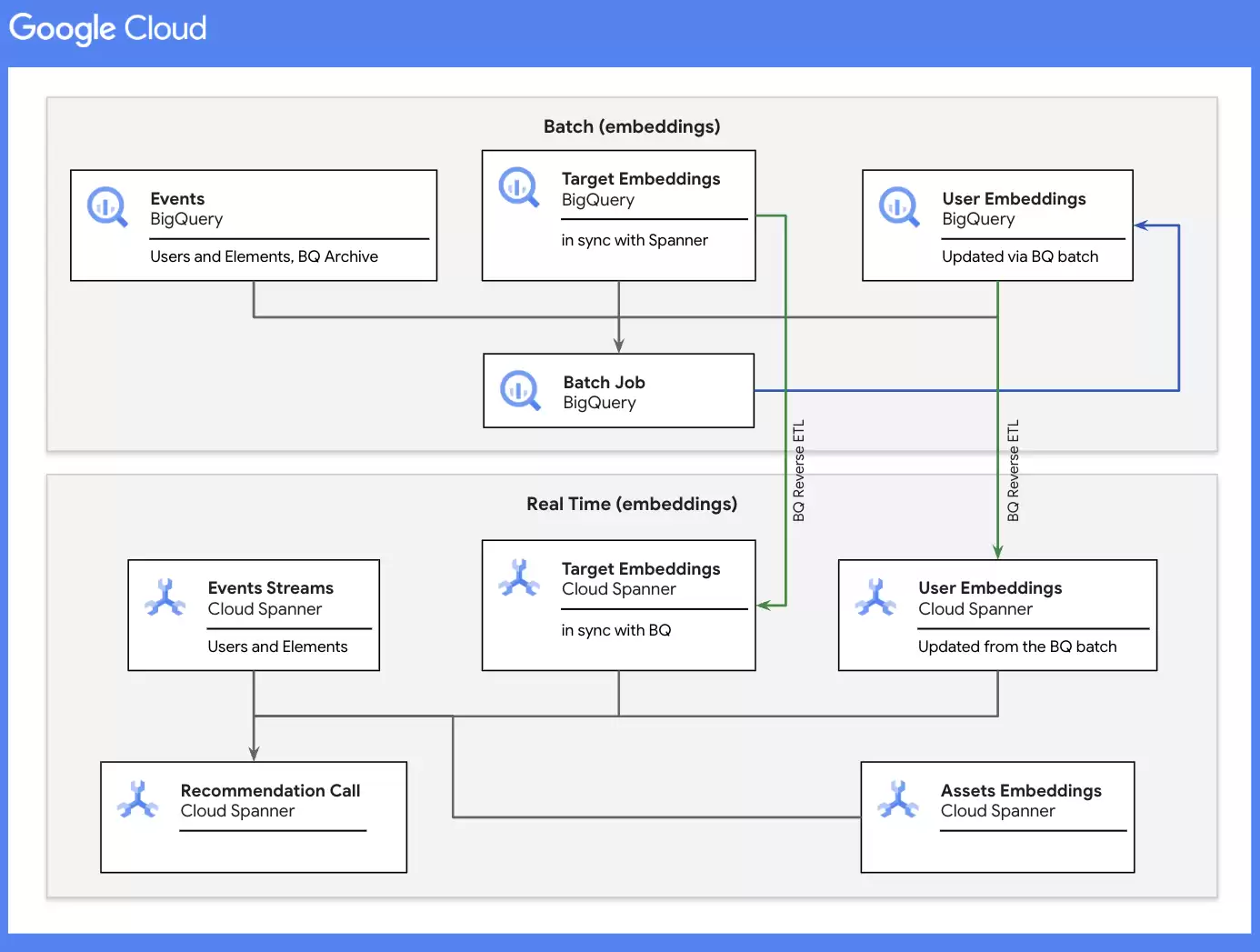
如上所示,通过实时与批处理流程相结合,即可覆盖用户的每一次交互,并根据用户当前的“空间与时间”背景推荐与其喜好相匹配的产品和服务。
更重要的是,这套架构亦具有弹性,可根据用户流量及应用需求进行灵活扩展。
原文标题:Real-Time Recommendations Powered by Spanner, BigQuery, and Vector Embeddings,作者:Yogesh Tewari




