从GPT系列、Gemini到DeepSeek、QWen的快速更新,模型训练迭代时间已缩短至不足3个月,在当今生成式人工智能高速发展的浪潮中,AI模型的规模和复杂度不断攀升,迭代速度也在缩短,如何高效、稳定地生产先进AI模型,成为了科技竞争的核心焦点。
大模型训练对算力、效率和系统稳定性的高要求,催生了全新的基础设施理念——“AI工厂”。

摩尔线程创始人兼CEO张建中在世界人工智能大会(WAIC 2025)开幕前夕的技术分享会中表示,为应对生成式AI爆发式增长下的大模型训练效率瓶颈,摩尔线程将通过系统级工程创新,构建新一代AI训练基础设施,致力于为AGI时代打造生产先进模型的“超级工厂”。
生产先进模型的超级工厂,不仅代表了AI算力架构的创新,更象征着从芯片设计到大规模集群协同的系统级工程升级。
什么样的基础设施能够称之为AI工厂?
可以类比传统的工厂。首先,它必须拥有强大且通用的计算引擎,能够支撑从训练、推理到实际部署的全流程AI生产。其次,AI工厂不是冷冰冰的算力堆叠,更是一套系统性的工程创新集合,包括硬件架构优化、软件系统协同、高效能集群建设和持续稳定的运行保障。
这些要素共同转化为更高的AI生产效率和更低的应用门槛,从而推动通用人工智能的产业化进程。

摩尔线程提出的“AI工厂”,如同芯片晶圆厂的制程升级,是一个系统性、全方位的变革,需要实现从底层芯片架构创新、到集群整体架构的优化,再到软件算法调优和资源调度系统的全面升级。通过全方位的基础设施变革,推动AI训练从千卡级向万卡级乃至十万卡级规模演进,以系统级工程实现生产力和创新效率的飞跃。
张建中指出,“AI工厂”的智能“产能”,由五大核心要素共同决定,其效率公式可概括为:AI工厂生产效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性。

提升AI生产效率的五大核心要素
加速计算通用性、单芯片有效算力、单节点效率、集群效率、集群稳定性这五大核心要素,恰好是系统由小到大,从硬件到软件再到系统的关键。
1. 加速计算通用性
摩尔线程的构建AI工厂是以自研的全功能GPU通用算力为基石,具备全功能GPU具备“功能完备”与“精度完整”特性,在国内芯片公司中独具优势。
摩尔线程基于自研MUSA架构的全功能GPU,单芯片即可集成AI计算加速(训推一体)、图形渲染(2D+3D)、物理仿真和科学计算、超高清视频编解码能力,充分适配AI训推、具身智能、AIGC等多样化应用场景。

而全功能GPU支持从FP64至INT8的完整精度谱系,原生支持FP8大模型训练及推理,并通过FP8混合精度技术,在主流前沿大模型训练中实现20%~30%的性能跃升,为国产GPU的算力效率树立行业标杆。
这种通用性不仅极大提升了硬件资源利用率,降低了系统冗余和开发成本,更为未来世界模型和新兴AI形态的动态演进提供了坚实底座。
2. 单芯片有效算力
高效芯片并非只谈峰值算力,更考验实际应用场景下的“有效算力”,摩尔线程通过三大突破——计算、内存、通信,显著提升单GPU运算效率。

运算效率依赖于架构,摩尔线程创新的全功能、多引擎、可配置、可伸缩GPU架构,通过硬件资源池化及动态资源调度技术,构建了全局共享的计算、内存与通信资源池,允许根据目标市场快速裁剪出优化的芯片配置,大幅降低了新品芯片的开发成本,在保障通用性的同时显著提升了资源利用率。

在计算层面,AI加速系统(TCE/TME)全面支持INT8/FP8/FP16/BF16/TF32等多种混合精度计算。其中FP8技术通过快速格式转换、动态范围智能适配、高精度累加器等创新设计,在保证计算精度的同时,将Transformer计算性能提升约30%。
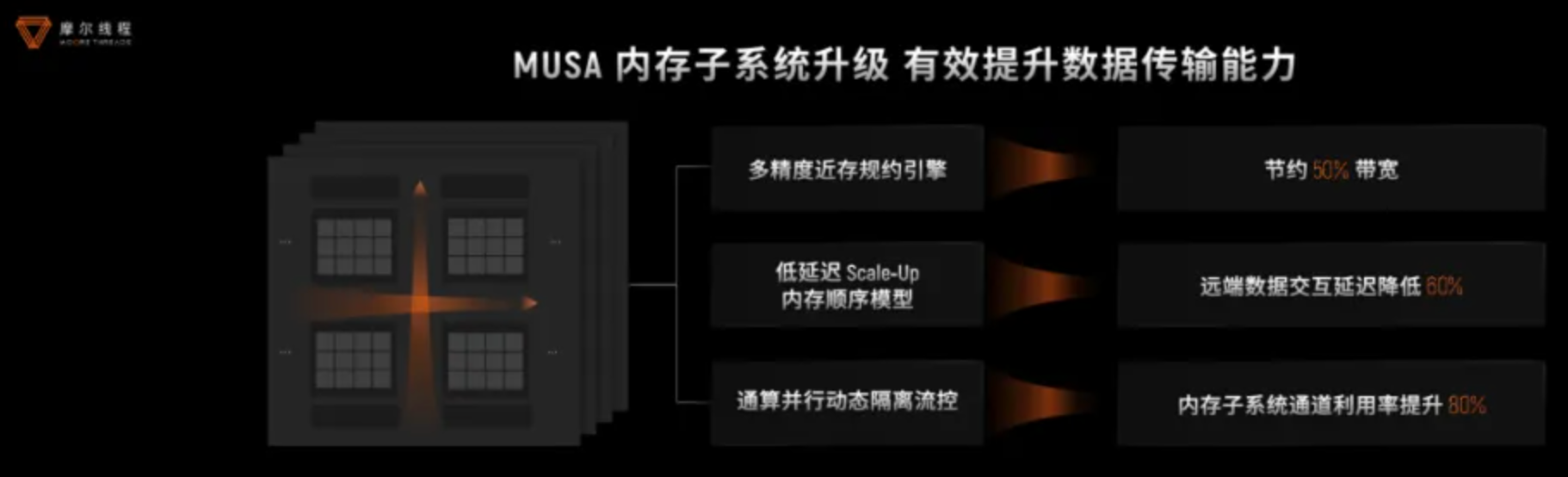
内存优化方面,通过多精度近存规约引擎、低延迟Scale-Up、通算并行资源隔离等技术,内存系统实现了50%的带宽节省和60%的延迟降低,有效提升数据传输能力。

通信效率的优化,是通过独创的ACE异步通信引擎减少了15%的计算资源损耗。另外,MTLink2.0互连技术提供了高出国内行业平均水平60%的带宽,为大规模集群部署奠定了坚实基础。
3. 单节点效率
单芯片的有效算力高还不够,节点层面的执行效率,更是AI工厂整体效能的基础。
摩尔线程是通过MUSA全栈系统软件实现关键技术突破,其中的核心包括了五个方面:
首先是任务调度优化,核函数启动(Kernel Launch)时间缩短50%。其次是极致性能算子库,GEMM算子算力利用率达98%,Flash Attention算子算力利用率突破95%。然后是通信效能提升,MCCL通信库实现RDMA网络97%带宽利用率;基于异步通信引擎优化计算通信并行,集群性能提升10%。还有低精度计算效率革新,FP8优化与行业首创细粒度重计算技术,显著降低训练开销。以及开发生态完善,基于Triton-MUSA编译器 + MUSA Graph实现DeepSeek-R1推理加速1.5倍,全面兼容Triton等主流框架。
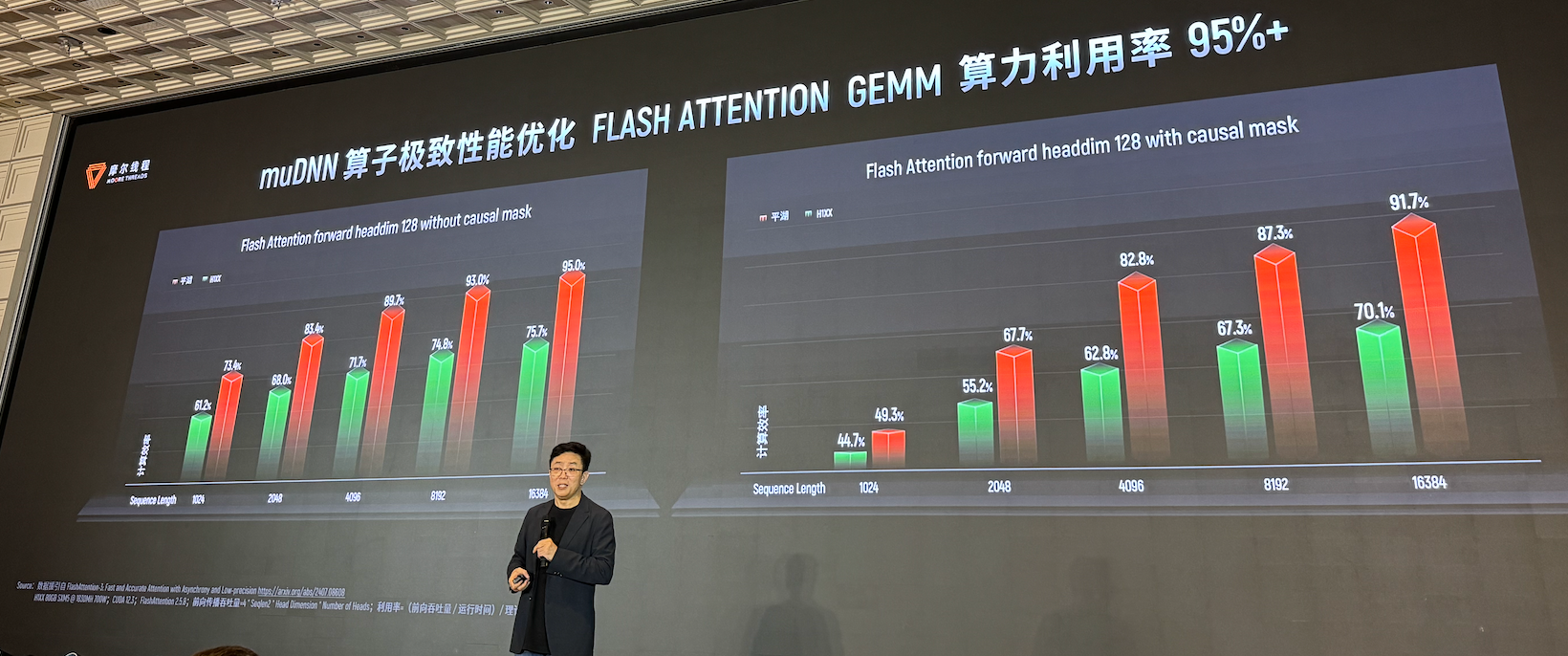
强大的单节点处理能力,不仅能够缩短大模型单机训练时间,更能在AI推理和实际业务部署中实现更低延时和更高吞吐,显著提升每台设备的投资回报率。这也为边缘计算、私有部署等行业AI场景提供了强力支持。
4. 集群效率
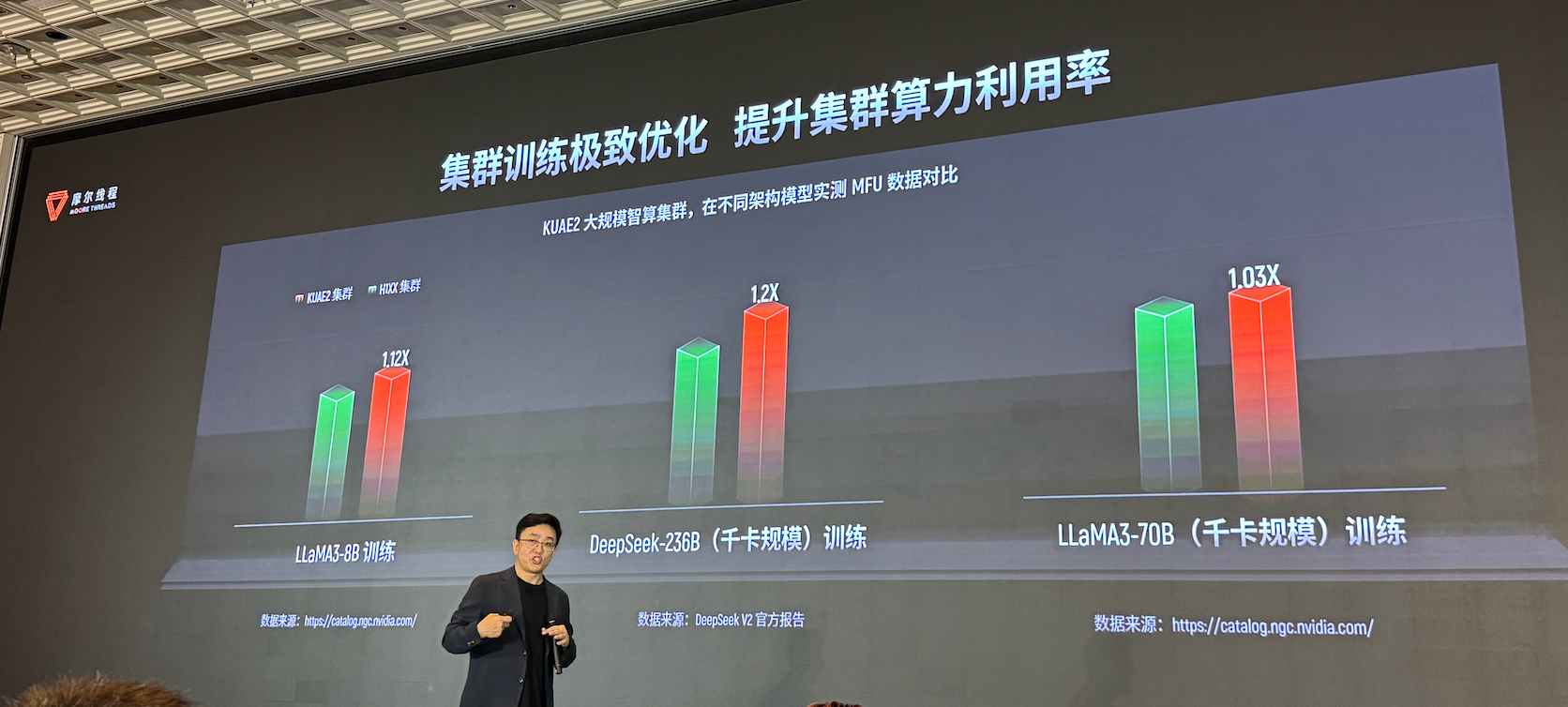
AI工厂是成千上万甚至十万块GPU高效协同的大规模集群。摩尔线程自研KUAE计算集群通过5D大规模分布式并行计算技术,实现上千节点的高效协作,推动AI基础设施从单点优化迈向系统工程级突破。
其中,创新5D并行训练通过整合数据、模型、张量、流水线和专家并行技术,全面支持Transformer等主流架构,显著提升大规模集群训练效率。
性能仿真与优化,通过自研Simumax工具面向超大规模集群自动搜索最优并行策略,精准模拟FP8混合精度训练与算子融合,为DeepSeek等模型缩短训练周期提供科学依据。
还有秒级备份恢复,针对大模型稳定性难题,创新CheckPoint加速方案利用RDMA技术,将百GB级备份恢复时间从数分钟压缩至1秒,提升GPU有效算力利用率。
根据摩尔线程给出的数据,基于平湖架构KUAE2智算集群,无论千卡集群或更大规模,在每个应用场景都能做到比国外主流产品更高的性能和效率,达到行业领先水平。
5. 集群稳定性
即便集群的效率再高,对于任何大规模训练任务,可持续产出的稳定性才是真正的护城河。
为此,摩尔线程创新推出零中断容错技术,故障发生时仅隔离受影响节点组,其余节点继续训练,备机无缝接入,全程无中断。这一方案使KUAE集群有效训练时间占比超99%,大幅降低恢复开销。
同时,KUAE集群通过多维度训练洞察体系实现动态监测与智能诊断,异常处理效率提升50%,让用户看得见和管理得到每一个训练集群的每一片GPU。再结合集群巡检与起飞检查,训练成功率提高10%,为大规模AI训练提供稳定保障。
张建中说,“摩尔线程的AI工厂从五个点分别去做很多的工作提升能力,我们高效率的工厂等于全功能的GPU X MUSA统一系统架构X全栈软件栈X高效的KUAE集群X零中断。只有这样的组合,才能确保每一个环节都做到最好,100% X 100% X 100%才能确保100%的成功率。”

AI工厂将加速哪些行业的发展?
完善的“AI工厂”不仅需要高效训练大模型,还需具备推理验证能力。

摩尔线程基于自研MUSA技术栈,构建覆盖LLM、视觉、生成类模型的全流程推理解决方案,实现“训练-验证-部署”的无缝衔接。其MT Transformer自研推理引擎、TensorX自研推理引擎和vLLM-MUSA推理框架,为模型验证和部署提供极致性能支持。
摩尔线程的数据显示,其旗舰产品MTT S5000满血跑DeepSeek R1模型推理,速度达到100 tokens/s,达到行业领先水平。
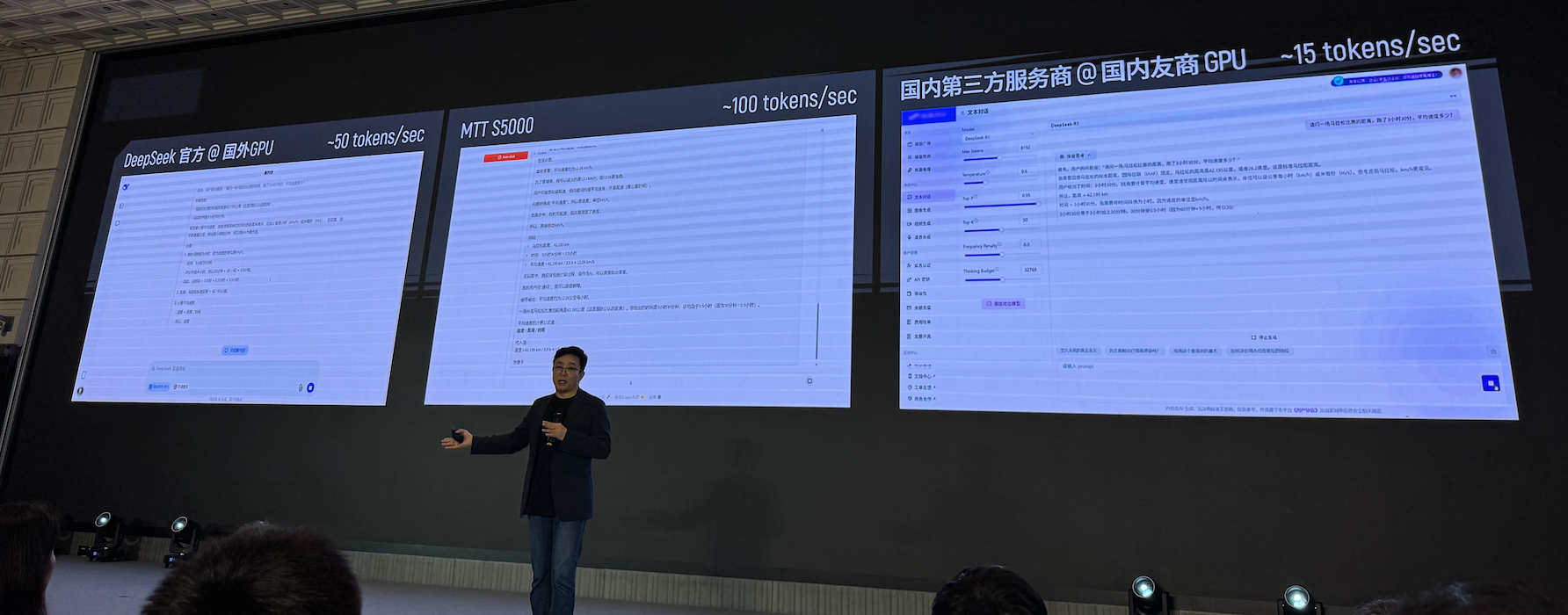
这就意味着,AI工厂驱动的不仅是AI产业自身的技术跃升,更是各行各业智能化升级的关键引擎,摩尔线程以“KUAE+MUSA”为智算业务核心,将加速众多行业的发展。
比如AIGC与内容创作:通过超大规模模型训练,实现更高质量的文本生成、图像、音频和视频内容创作,催生数字媒体、广告动漫等新业态爆发。
科学计算与工程仿真:AI工厂全功能GPU在物理仿真、药物研发、材料设计中高效支持科学建模与大数据分析,推动科研创新周期大幅缩短。
工业智能体与智能制造:AI工厂支持工业领域的大模型训练和实时推理,提升自动化工厂、机器人、工业检测等核心环节的智能化水平,实现生产降本增效、精益管理。
医疗影像分析:高效算力赋能医学图像分析、病理识别和疾病诊断,助力医疗智能化升级与普惠健康。
智慧交通与智能驾驶:通过海量传感器数据的实时处理与模型训练,为自动驾驶、高速公路管理、城市交通优化提供坚实算力基础。
具身智能与智能体:全能GPU支持具身智能AI体在虚拟与物理环境间、高效进行感知、思考与运动控制,推动智能机器人、虚拟人等前沿发展。
摩尔线程在2025世界人工智能大会(WAIC)的站台上也展示了在上述场景中的应用。
可以看到,摩尔线程“AI工厂”力图打破算力桎梏,为千行百业的数智化转型提供底座。从图形渲染到AI算力引擎,从全功能GPU到系统级优化,其五大核心技术要素构筑的不只是一个“生产先进模型的超级工厂”,更是AGI新时代产业智能升级的动力源泉。




